Dúvidas frequentes¶
Chamadas API¶
Porque recebo resposta HTTP 400 e mensagem “None is not of type ‘object’”?¶
Experimente o envio do campo Content-Type do header http em todo request à API como sendo application/json.
Veja mais detalhes em Introdução.
Posso fazer chamadas à API para ler as novidades no monitoramento?¶
A API funciona de dois modos. Ou empurramos os resultados para o sistema do cliente, ou eles leem os eventos de nossa API.
Recomendamos fortemente a primeira forma, em que nós chamamos um endereço HTTP do cliente para empurrar os eventos. Porque sempre vamos chamar só para o que for novidade, controlado duplicações etc e vamos garantir que o cliente retornou HTTP 200, senão vamos retentando até 13 vezes cada chamada individualmente.
No segundo modo, seria uma chamada assim
(para a URL /api/monitored_event). Esta modalidade faria sentido se por
questoes de segurança uma instalação do sistema do cliente não pode ter um
servidor HTTP aberto para o mundo, ou para nossos IPs. Nessa modalidade é
importante que o cliente chame no máx 2x ao dia. E também precisa controlar do
lado do cliente o que já foi lido ou nao. Essa URL lista todos os eventos que
geramos, então o cliente precisa ficar filtrando (via argumento ?where={..} na
URL) para listar só os eventos com data de “ontem”. Veja exemplo.
A API envia os eventos para um unico webhook ou eu posso cadastrar varios webhooks para receber cada tipo de evento?¶
No momento, e até pra simplificar, a API envia todos os tipos de eventos para um único endereço.
Cada empresa (user_company) dentro da API pode ter um endereço de webhook diferente.
A API aceita chamadas HTTP (porta 80)?¶
Nossa API trabalha somente em HTTPS (TCP porta 443). Ao fazer um request HTTP (porta 80) ao servidor em
op.digesto.com.br, ele retorna um HTTP Response 307 (Redirect) com o mesmo path
e host, porém trocando o protocolo para HTTPS. Ou seja, uma Request URL:
http://op.digesto.com.br/api/user_company vai receber HTTP response status 307 e
com o header da response Location: https://op.digesto.com.br/api/user_company.
Isso tudo normalmente é transparente para clientes HTTP (browsers, API de
programação etc).
Erro de certificado HTTPS “unable to find valid certification path to requested target” com cliente Java¶
Versões mais antigas do JDK não incluem o certificador raiz DST Root CA X3 que usamos (Letsencrypt). Uma alternativa é desabilitar a validação de certificadores raiz no JDK, ou importar definições mais atualizadas no ambiente Java.
Não estou recebendo as chamadas em meu sistema com os eventos de monitoramento¶
Certifique-se que:
- Em Configurações > Integração via API a URL que devemos chamar em seu ambiente é uma URL válida, e que a checkbox “Habilitado” está marcada.
- As partes e processos para as quais resultados são esperados estão com o monitoramento habilitado.
- Que as chamadas geradas pela nossa API são listadas na tela de “Integração via API”, na seção “Detalhes das últimas 20 chamadas” e que os retornos do seu sistema na seção seguinte dessa tela fazem sentido.
Como saber quais chamadas de callback (webhook) falharam definitivamente?¶
Vocês podem listar as chamadas que desistimos após 5 dias (13 tentativas) acessando via API esse endereço:
op.digesto.com.br/api/webhook_call?where={"retries":13,"called":false}&sort={"created_at":false}
Ele lista os detalhes de cada chamada, onde o campo request_body é o conteúdo que seria enviado.
Como validar o token de acesso à API?¶
Uma forma é fazer uma chamada para https://op.digesto.com.br/api/user/current usando o token a ser testado.
No json retornado (status HTTP 200) deve vir o token de volta no campo api_key.
Se o token for inválido ou ausente, a API retorna um content-type diferente de application/json
e também não retorna um json com o campo api_key.
Como saber de qual empresa é um evento, quando recebo eventos de várias empresas no mesmo endereço HTTP de retorno?¶
Quando fazemos uma chamada ao servidor de vocês avisando sobre uma nova movimentação, ou publicação, ou distribuição, enviamos uma lista de eventos, e cada evento contém sempre dois campos que permitem identificar de quem é o processo:
source_url: (array) - lista de endereços das entidades monitoradas que originaram o evento. Assim você pode saber a qual processo essa publicação se refere, ou a qual parte monitorada etc
source_user_custom: (string) - valor do campo user_custom para o objeto que originou o evento. Quando se define um processo ou pessoa para ser monitorada é possivel especificar o campo user_custom (por exemplo um ID interno da base do cliente).
api_name: (string) - valor do campo de mesmo nome da user_company à qual esse evento se refere. Este campo da user_company pode ser alterado via uma chamada HTTP PATCH.
Não recebi eventos de monitoramento pois todas as 13 tentativas falharam. Como faço para receber?¶
Você pode obter detalhes das tentativas de envio de eventos de monitoramento para um processo indo no menu Configurações > Buscar eventos. No excel enviado por e-mail a partir dessa tela, há a data em que os eventos de monitoramento com falha no envio foram gerados.
Uma alternativa para fazer o reenvio então é ir em Configurações > Integração via API e no formulário Solicitar reenvio de chamadas feitas pela Digesto, colocar uma faixa de datas que cubra o dia-hora em que os eventos foram gerados pela Digesto na API, e solicitar o reenvio.
Essa opção marca todos os eventos de monitoramento (esse reenvio se aplica a todos os tipos: distribuicoes, andamentos etc) de uma faixa de datas para reenvio. Vamos começar a reenviar, cerca de 15 minutos depois, copias exatas de dados já enviados. Essa operação não tem custo (faturamos eventos de monitoramento uma única vez). Só é importante confirmar que do seu lado as informações vão ser reescritas sem problemas, e que sua lógica não descartará eventos de monitoramento com data de criação antigas. Para volumes altos de eventos (200+ dia) recomendamos solicitar em lotes de 1 dia.
Outra alternativa, caso já conheça o número CNJ do processo cujos dados deseja consultar, é usar a chamada detalhes do processo em nossa base judicial.
Monitoramento¶
Ao reativar parte monitorada, enviamos resultados retroativos?¶
Sim. As partes monitoradas estão sempre retroagindo os cálculos, comparando data de distribuição com data de hoje, e checando se já enviamos ou não um resultado/processo.
Para contornar esse comportamento padrão, é possível mudar na página de detalhes da parte monitorada esse campo:
Critérios adicionais de monitoramento > Distribuídos após data fixa (inclusive)
e colocar para a data de hoje (ou data em que des-excluírem ou reativarem a parte monitorada). Isso deve ser feito antes da reativação.
Quando faço ajustes à expressão de busca de uma parte monitorada, resultados retroativos são enviados?¶
Sim. As novas ocorrências deveriam ir pela API tão logo as expressões de busca da parte monitorada fossem corrigidas/modificadas.
Elas seriam enviadas justamente por causa da lógica de olhar as distribuições de cada Parte Monitorada até 90 dias atrás e enviar tudo o que ainda não tiver sido enviado.
Essa lógica vale para qualquer parte monitorada, independente de ser novo ou antigo: algumas vezes ao dia verificamos em nossa base todos os processos distribuídos ha até 30 dias que obedeçam às expressões configuradas de cada parte, e o que for novidade, enviamos.
Essa quantidade (default 90) é configurável pela Digesto, por parte monitorada.
É possível monitorar nomes de partes pelo CNPJ ou CPF e evitar resultados de processos de homônimos?¶
Não. A filtragem de quais processos recem distribuidos são resultados para as partes monitorados é sempre feito usando o nome mesmo pois o nome da parte é o mínimo denominador comum de todos os tribunais, poucos mencionam o CPF da parte, a maioria menciona só o nome (e com erros frequentes de grafia). Assim para determinar os resultados (novas distribuições) consideramos apenas o nome monitorado.
Existe a opção de uma empresa na API, chamada “Extrair CPF/CNPJ da petição inicial”. Ela se aplica apenas ao campo de documento das partes (um dos dados de cada tupla que descreve as partes do processo no campo partes). Quando a opção está habilitada, só incluimos o número do documento para as partes que conseguimos confirmar dentro da petição inicial.
Um mesmo processo ou nome pode ser cadastrado duas vezes se estiverem em empresas diferentes?¶
Sim, podem. E vão gerar eventos (distribuicao, publicações, movimentacoes etc) distintos, para cada empresa (user_company) onde for cadastrado.
No caso de nomes monitorados em duplicidade dentro em uma empresa, ou partes monitoradas com nomes redundantes, para a mesma empresa, um novo processo distribuído gera apenas uma notificação.
Da mesma forma, a cobrança é por ocorrência de processo distribuído, desconsiderando duplicados. A API por sí só já descarta resultados duplicados antes de enviar novas distribuições. Se cadastrar para monitorar por exemplo “BANCO ITA” e em outra parte cadastrar a expressão “BANCO ITAU”, teoricamente todo processo do ITAU seria uma nova distribuição para essas duas partes monitoradas, mas só enviaremos (e cobraremos) cada processo uma vez só dentro da mesma empresa na API.
Como verifico se um evento de monitoramento envolvendo processos foram gerados?¶
Você consegue gerar um relatório com os eventos gerados pelo CNJ.
Basta entrar com o usuário administrador da empresa filha e seguir o seguinte caminho :
No menu do lado esquerdo, seguir o caminho “Configurações”->”Buscar eventos”. Seria a última opção do menu.
Você será direcionado para a tela onde basta indicar os CNJ´s que gostaria de saber se/quando teve evento gerado. Importante não esquecer de confirmar o tipo de serviço que gostaria de saber (normalmente “distribuicoes” ou “movimentação de processos”).
O relatório será enviado para o e-mail logado (Administrador da conta).
As primeiras distribuições de uma nova parte monitorada não estão vindo com anexos¶
A obtenção das cópias dos anexos/iniciais dos processos é realizada apenas para os processos obtidos pelos nossos robôs em data posterior ao cadastro de uma nova parte monitorada.
Como logo após o cadastro de uma nova parte monitorada há o envio de distribuições retroativas (processos obtidos pelos robôs e/ou distribuidos antes da data do cadastro), estas normalmente não contém as iniciais.
Em geral significa que após 24h do cadastro, as novas distribuições enviadas contarão com anexos (quando disponibilizados pelo site do tribunal).
Quando se ativa uma parte monitorada por distribuição nova, configurada com o envio retroativo de distribuições, recomendamos solicitar à Digesto um “due diligence” prévio, para enriquecer nossa base de anexos, antes de ativar o monitoramento da parte na API Digesto.
A mesma lógica acima se aplica para alterações nas partes monitoradas como: expressão de busca e tribunais escolhidos. Estas mudanças podem gerar resultaods para muitos processos antigos, onde as regras para obtenção de anexo não se aplicariam e os processos seriam enviados via API sem os anexos.
É possível usar o modulo de monitoramento de distribuição para pegar processos mais antigos de uma parte monitorada?¶
É possível sim, o período em que retroagimos a data de distribuição do processo para enviar resultados de uma parte monitorada é configurável por parte monitorada, mas tem essas ressalvas:
- trials e cortesias não se aplicam
- nao baixamos anexo das iniciais para estes retroagidos
- limitado a 365 dias
- enviaremos todos os processos com data de distrib. nesse intervalo de datas, sem atualizar os dados do processo. Então não conseguimos dizer/filtrar se o processo já não foi arquivado, extinto etc.
Qual a lógica de descoberta de novos processos usada no sistema do tribunal?¶
Usamos um combinado em constante evolução de técnicas distintas para descobrir a existência de um novo processo e consultar os dados de capa dele o mais rápido possível. A pergunta seguinte detalha mais pontos.
Atraso na captura das distribuições de processos¶
A descoberta de novos processos por nossos robôs é um processo totalmente automatizado e depende muito da disponibilidade dos sites dos tribunais e bloqueios a consultas automatizadas que os mesmos impõem, que podem causar atrasos na captura. Estamos sempre monitorando esse tempo médio entre nossa primeira captura e a distribuição no tribunal, e fazendo melhorias contínuas nos robôs para contornar bloqueios e indisponibilidades, para assim evitar atrasos.
Alguns tribunais demoram alguns dias após a distribuição para deixar os processos visíveis em seus sites, o que pode também contribuir com atrasos.
Outro motivo possível é que o comportamento padrão da API (pode ser configurado por empresa) é continuar pedindo para nossos robôs obterem os autos digitais por até 48h após descobrirmos o processo pela primeira vez. Se não conseguirmos até esse prazo (ou se o processo não tiver autos/não for digital), o processo é enviado via API da forma que estiver. Fazemos assim para garantir que vamos obter o máximo possível de anexos para as distribuições, mas também sem gerar muito atraso.
Um terceiro motivo é quando, no momento em que capturamos estes processos, a parte monitorada não constava no tribunal associada ao processo, então era impossível nosso robô saber que o processo era de interesse. Isso pode acontecer quando capturamos o processo muito próximo à data da distribuição, ou quando há erro do requerente ao não informar a parte ré correta. Em alguns casos específicos onde há uma publicação clara em diário oficial posterior à nossa primeira captura mencionando a parte monitorada, nossos robôs tentam uma re-consulta dos detalhes do processo no site do tribunal tribunal para confirmar se a parte passou a figurar nos polos. Nesse momento o processo seria então enviado via API.
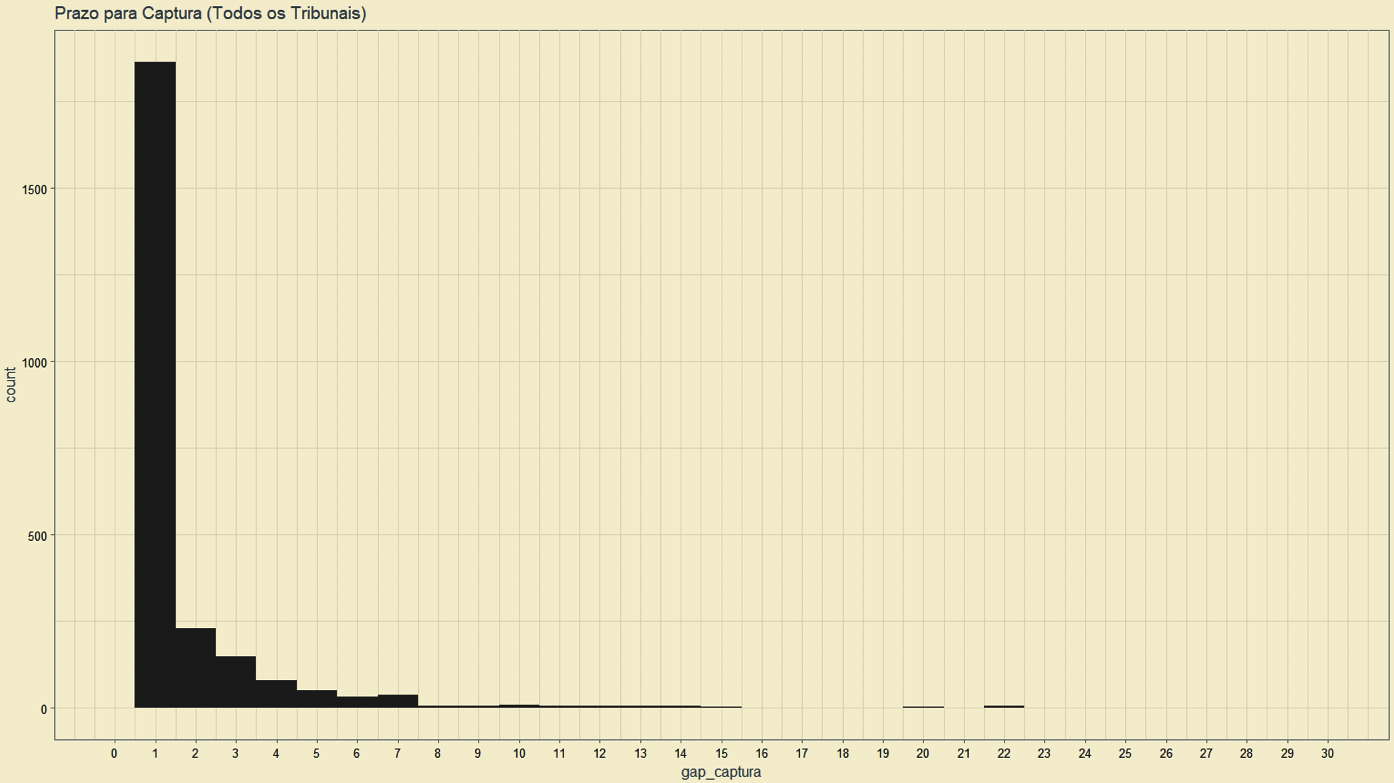
Histograma do tempo (dias) entre a data da distribuição e data de obtenção pela Digesto.
Atraso na captura e envio de publicações¶
Enviamos os resultados de publicações em média 4h após a disponibilização dos diários no site do tribunal, porém há diários/cadernos onde o lag é maior. Este lag é afetado por questões de nossa infraestrutura interna e de fatores externos. As internas estamos sempre atuando em melhorias para reduzir ao máximo este tempo pois entendemos a importância e tempestividade de informações jurídicas. Os externos, como bloqueios nos tribunais, arquivos publicados corrompidos, mudanças em formatos de dados/PDFs sem aviso prévio, indisponibilidades, publicações retroativas com datas erradas, falta de padrões etc naturalmente fogem de nosso controle, embora usemos diversas técnicas para reduzir o impacto.
Há variação no prazo de captura de processos após distribuição entre os tribunais?¶
Sim. Alguns tribunais disponibilizam os dados do processo mais rapidamente após a protocolação do mesmo ou possuem infraestrutura de TI que possibilita maior rapidez nas consultas, fazendo com que consigamos obter os dados do processo logo após a distribuição.
Alguns tribunais só tornam o processo visível para consultas no dia seguinte à distribuição, ou apresentam indisponibilidades frequentes ou bloqueios diversos a acessos automatizados.
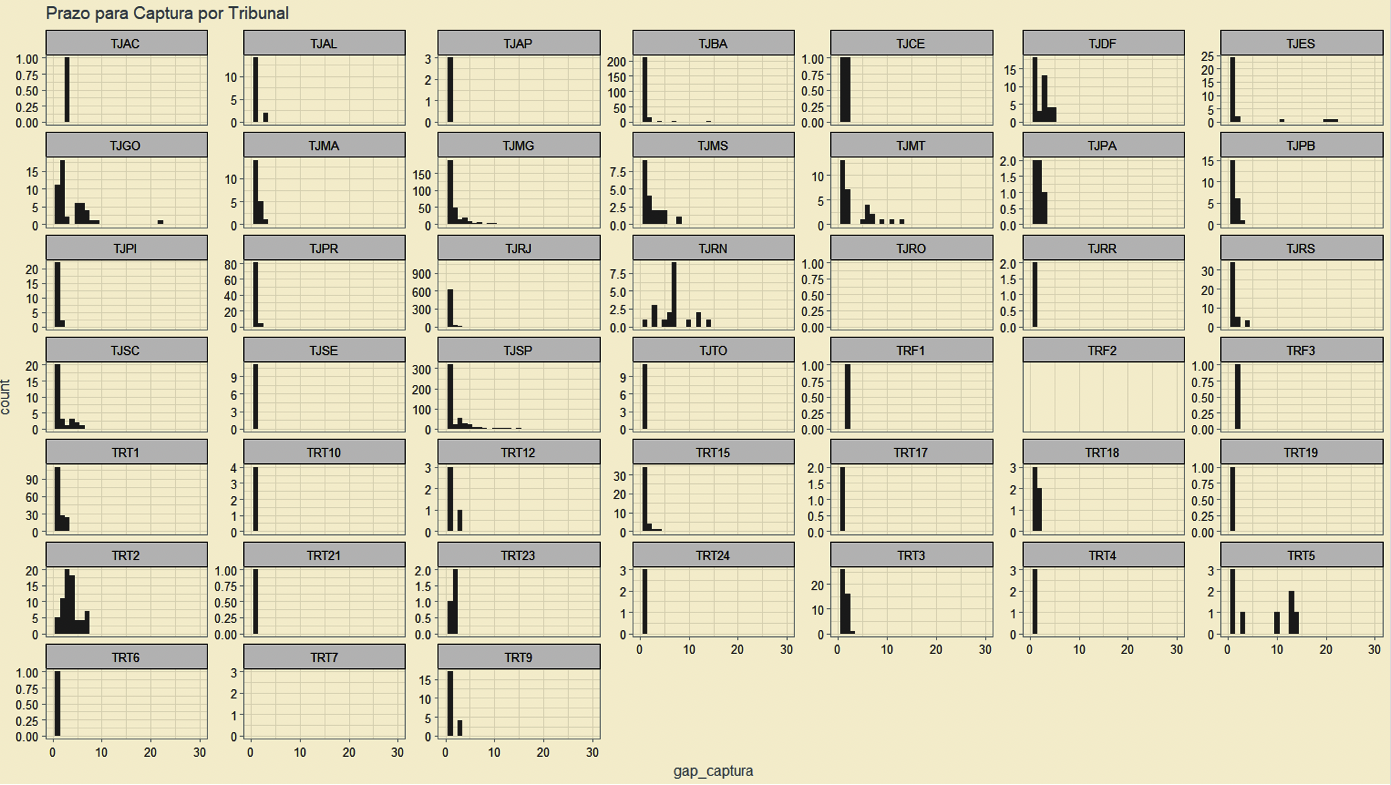
Histograma do tempo (dias) entre a data da distribuição e data de obtenção pela Digesto, por tribunal.
Porque há uma redução na quantidade de processos distribuídos na segunda-feira?¶
Normalmente enviamos num dado dia os processos distribuídos ao longo dos últimos dias. Então ao longo do final de semana enviamos os processos distribuídos na sexta-feira, e, na segunda-feira, os distribuídos no final de semana, quando há pouca distribuição.
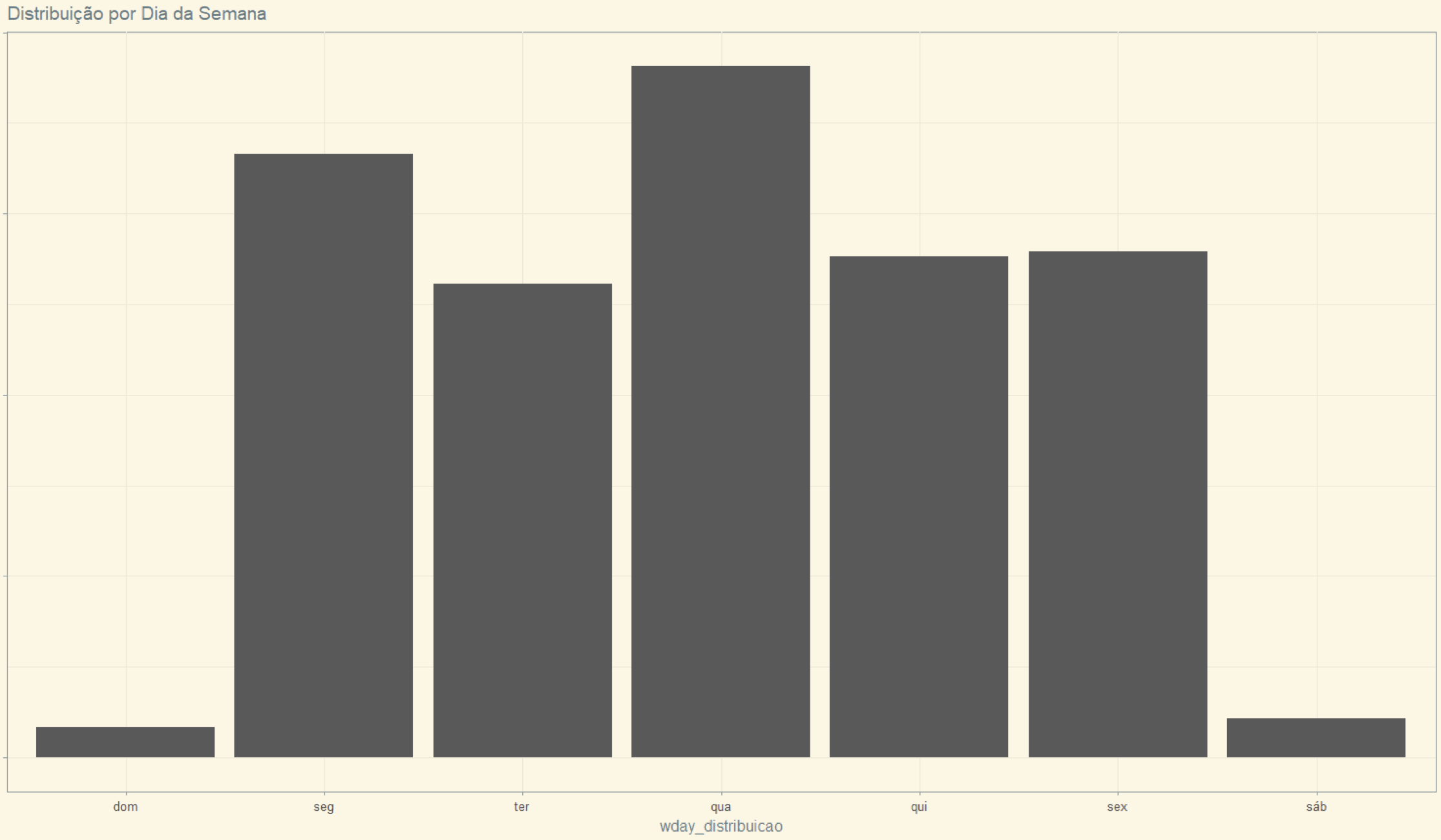
Histograma da quantidade de processos distribuídos por dia da semana
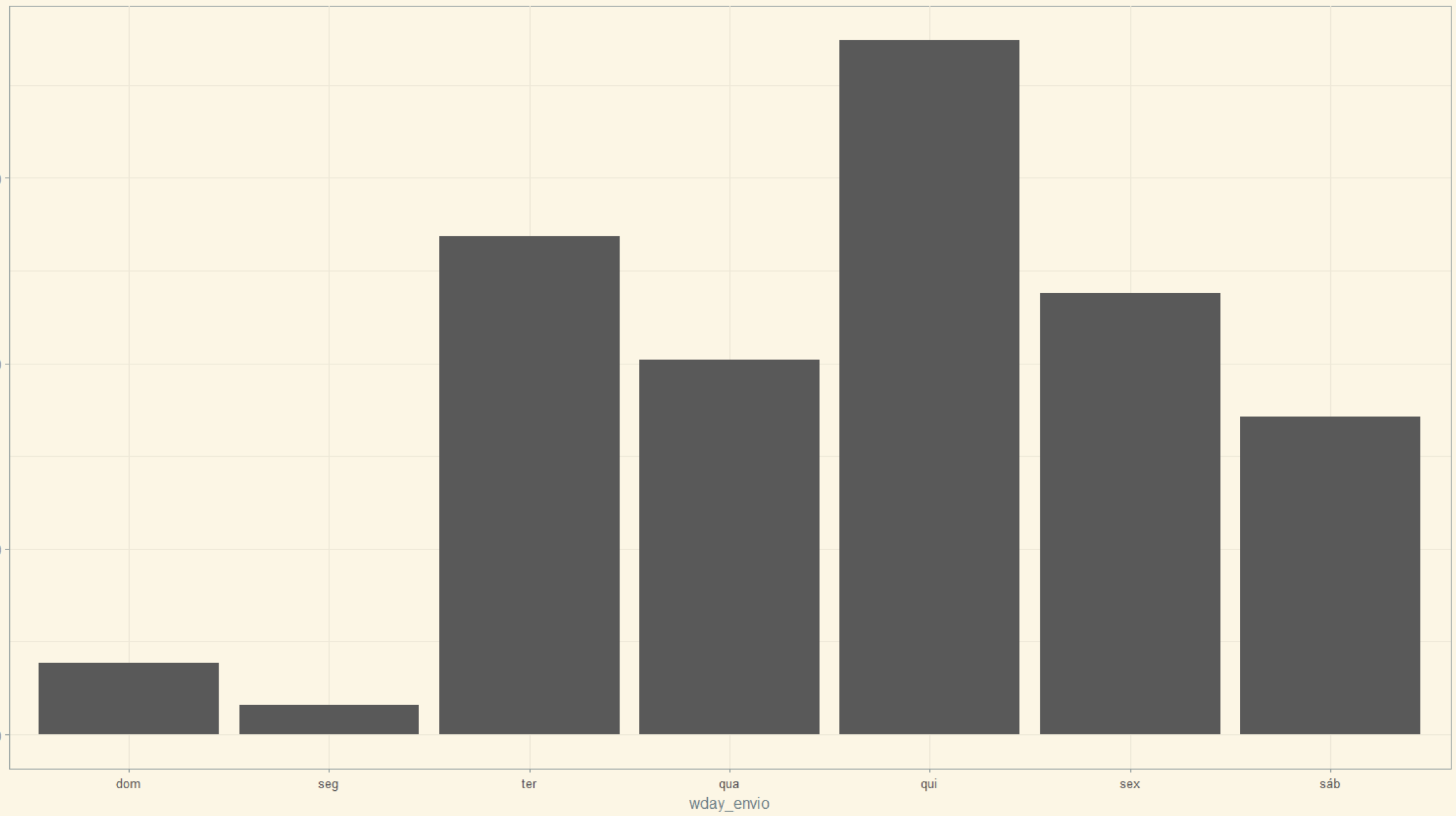
Histograma da quantidade de distribuições enviadas via API por dia da semana
Quanto tempo demora para baixar os autos de um processo?¶
Varia conforme a demanda, disponibilidade e tempo de resposta do tribunal, na média entre 1 e 2 horas mas há casos em que a operação de baixar os anexos dos sites dos tribunais é bem sucedida somente na madrugada.
Há casos onde o tribunal só disponibiliza os autos algumas horas, ou dias, após a distribuição.
Quanto tempo demora em média para atualizar os dados de processos no tribunal por demanda?¶
Varia por tribunal, conforme a demanda e carga no momento sobre cada tribunal. Alguns apresentam indisponibilidades temporárias, com duração que foge de nosso controle. Na média, em muitos tribunais conseguimos retornar entre 2 e 4 horas, mas há casos em que a operação de atualização dos dados é bem sucedida somente na madrugada. Nossos sistemas fazem tentativas por até 12 horas. Nos casos onde não ocorrer retorno nosso, não haverá cobrança, e recomendamos enviar novamente o pedido de atualização após esse período.
Como monitorar processos por citação?¶
Primeiro precisaria colocar o processo para monitorar.
Então vamos gerando eventos com novos andamentos destes processos. Cada andamento é um array de dados, com este schema. O 6o item do array é o resultado de um classificador nosso. Se tiver alguma tupla (30,x) ou (3,1), é porque encontramos indício de citação no andamento, logo o processo provavelmente foi citado.
Quando monitoramos o processo, geramos eventos de mudanças nos atributos de processos que serviriam para sinalizar (dentro outros dados cadastrais do processo) que “apareceu” um advogado para um réu, um indício forte de citação do reu.
Precisamos monitorar pessoas físicas e cadastramos essas pessoas como partes monitoradas com Nome + CPF, mas o CPF não está sendo validado (trazendo falsos positivos)¶
Em nosso site web, ou via API (entidade /api/user_company), nos detalhes da
empresa existe a opção “Extrair CPF/CNPJ da petição inicial na consulta de CNJ à
base Digesto”. Porém ela se aplica apenas às validações que fazemos para
preencher o campo de documento das partes (um dos dados de cada tupla que
descreve as partes do processo no campo partes).
Quando a opção está habilitada, só incluimos o número do documento para as partes que conseguimos confirmar dentro da petição inicial.
A filtragem de quais processos recem distribuidos são resultados para as partes monitorados, é sempre feito usando o nome mesmo, pois infelizmente é o denominador mínimo comum de todos os tribunais pois poucos mencionam o CPF da parte, a maioria só menciona o nome mesmo.
Quando recebemos uma distribuição, geralmente temos o CPF da contraparte. Pelo que entendi, o CPF, é obtido no anexo. Assim, se não conseguiram pegar o anexo, não conseguiram pegar o CPF da parte também?¶
Correto, o dado do CPF e CNPJ das partes de uma distribuicao (evt_type=4) só enviamos quando for possivel confirmar que ele é mencionado nos anexos e que o nome é próximo do que consta na Receita Federal então se não tiver anexo não vamos enviar CPF/CNPJ.
Nós regularmente revisamos por amostragem os casos em que obtivemos a petição inicial e que acabamos enviando sem o CPF do autor. Esses casos podem ser porque de fato o advogado do autor errou o CPF da parte ao digitar a petição, ou o nome não bate pois foi usado o nome de casado/solteiro, coisas do tipo, ou a petição não está legível por máquina, ou então é um bug nosso nesse processo automático de conferencia/extração do CPF. Se vocês tiverem casos específicos onde o CPF do autor está legível e correto na petição inicial e nós deveríamos ter enviado com a CPF, então seria muito bom sabermos desses exemplos para analisarmos e corrigirmos eventuais bugs.
Porque nem todas as audiências são enviadas junto dos dados da distribuição de novo processo?¶
O serviço de captura de distribuição envia as audiências que estiverem disponíveis no tribunal no momento da captura. Nem sempre esse dado já está no tribunal quando a captura é feita, especialmente quando a captura é feita logo após a distribuição. Então nesses casos a informação é enviada pela API sem a audiência. O correto seria contratar também o serviço de monitoramento de processos, registrando cada processo recém-distribuído do cliente para ser monitorado via API, pois assim atualizaríamos os dados deles diariamente junto ao tribunal, sinalizando eventuais audiências.
Porque as distribuições de alguns estados não estão vindo com o valor de causa?¶
O padrão é só entregarmos esse valor na distribuição quando o tribunal apresenta esse dado na página de detalhes do processo. O TJRJ por exemplo não apresenta esse dado para os processos. Os tribunais trabalhistas também não apresentam por padrão um valor para a causa. É possível habilitarmos um comportamento opcional por empresa/cliente para extrairmos o valor da petição inicial, quando a mesma estiver legível por máquinas, mas fica sujeito a erro em alguns casos.
Porque estou recebendo poucas distribuições quando comparado com os processos obtidos durante o mesmo periodo por via tradicional?¶
A cobertura do serviço de distribuições não é 100%. Ela compreende apenas os processos fora do segredo de justiça e apenas os processos visíveis nos sites dos tribunais.
Usamos diversas técnicas pra ser o mais completo possível. Um problema comum é que as vezes o cliente final diz que “recebi em torno de 990” mas ele está dizendo “recebi 990 intimações ou citações em Jan” e nisso entram processos que foram distribuidos em Dezembro por exemplo.
Então há uma divergência de datas, porque nos nossos filtros para envio de distribuições consideramos a data da distribuicao do processo no tribunal.
Outro problema comum é um ajuste fino maior nos nomes e variações de partes. Uma medida boa é regularmente pegar os CNJs que o cliente final não recebeu pelo monitoramento Digesto e então nós obtemos esses processos, e estudamos as partes dos processos, para verificar se tem variacoes de nome ou grafia que deveriamos estar considerando e não estamos.
Por que não reportarmos distribuições em segredo de justiça?¶
Os processos em segredo de justiça requerem logins específicos do processo ou senhas, que não dispomos, para visualizar os detalhes do mesmo ou até saber de sua existencia. Ou então trazem só as iniciais dos nomes das partes, o que impossibilita identificarmos que o processo é de interesse de um cliente.
A atualização da captura das distribuições ocorre em determinado horário do dia?¶
Não há um horário fixo para o envio das distribuições pela API. Em média verificamos as novas distribuições dentro de nossa base e enviamos as novidades 6 vezes por dia.
Porque o layout dos anexos parece estranho e/ou sem formatação?¶
Neste caso o tribunal fornece o anexo apenas em formato HTML. Nesses casos, o que fazemos é converte-los para PDF automaticamente. Quando fazemos essa conversão, o arquivo HTML original pode ser consultado no mesmo endereço da versão PDF, só que removendo o “.pdf” no final do endereço. Ou seja, a URL ficaria terminando com “.html”. Como todo processo de conversão automática entre fomatos, o layout pode ficar diferente do que é exibido no site original. Em geral o que se perde é apenas o layout. Porém se alguma informação tiver sido truncada ou estiver ausente nessa versão em PDF, solicitamos que nos reporte para investigarmos melhor.
Como remover o monitoramento de um processo?¶
Qualquer entidade da API pode ser removida com um
HTTP DELETE para /api/proc/1111 onde 1111 é o ID Digesto para esse
processo monitorado (retornado pela API Digesto no momento em que o processo foi
registrado para monitoramento.
Alternativamente é possivel apenas desabilitar o monitoramento (para poder mais tarde reabilita-lo),
fazendo um HTTP PATCH para a URL do
processo monitorado, mudando o campo is_monitored do
processo monitorado em sí.
Caso você não possua o ID do processo monitorado, é possivel busca-lo na
API a partir do número CNJ, embora essa
forma não seja recomendada. Nessa alternativa você precisaria passar o número
formatado exatamente como usado no momento da criação do monitoramento, e caso
faça o filtro pelo campo numero_normalizado, deve normalizar da mesma forma
que fazemos: mantendo apenas dígitos e removendo zeros à esquerda.
É possível monitor publicações de um advogado mas só as envolvendo uma empresa?¶
Por exemplo o advogado tem nome JOAO e a empresa XPTO.
Nesse caso uma saída é na expressao regular (campo rex) dessa
monitored_person colocar (JOAO.*XPTO|XPTO.*JOAO), porém isso só funcionará
para o monitoramento de publicações, pois lá o match é no recorte inteiro. Para
distribuições não pois lá o match é só no nome da parte.
É possível filtrar o monitoramento pelo estado ou tribunal?¶
Sim, basta informar os tribunais desejados no campo tribunaisIDs da entidade
monitored_person (monitoramento distribuições).
No caso de monitored_term (monitoramento de publicações de palavras quaisquer),
use o campo sources.
Não recebi um processo via monitoramento de distribuições¶
Verifique se o processo já existe na base Digesto.
Caso ele já exista e as partes do processo e data de distribuição atenda aos critérios de monitoramento, e se o processo ainda não tem anexos/autos digitais, então o mais provável é que nossos robôs ainda estejam tentando baixar os autos antes de enviar.
O comportamento padrão da API (pode ser configurado por empresa) é continuar pedindo para nossos robôs obterem os autos por até 48h após obtermos o processo. Se não conseguirmos até esse prazo (ou se o processo não tiver autos/não for digital), o processo é enviado via API da forma que estiver. Fazemos assim para garantir que vamos obter o máximo possível de anexos para as distribuições, mas também sem gerar muito atraso.
Ou seja, a expectativa é que em menos de 48h este processo seja enviado.
Porque a ditribuição veio sem anexos?¶
Infelizmente o processo para obtenção de anexos de processos digitais não é infalível. Esta obtenção automática demanda bastante recurso computacional e de rede, e está sujeita a diversos bloqueios e falhas nos sites dos tribunais, que em geral são bastante instáveis.
Caso seja processo digital, o mais provavel é que nossos robôs ficaram tentando obter os anexos por 48h e como não conseguiram, enviamos os dados da distribuição sem os anexos. É um equilíbrio que fazemos entre pegar o máximo de anexos possível e não atrasar o aviso de distribuições.
Um paliativo que dispomos é configurar a empresa da API para que nossos robôs continuem tentando baixar os anexos desses casos por mais alguns dias, mesmo depois de enviar os processos para vocês sem anexos. Porém seria necessário programar uma lógica do lado de vocês para re-consultar este processo em nossa API nesse intervalo para checar se apareceram os anexos no processo que não tinha anexo.
Você pode reportar os eventos de distribuições sem anexo para o nosso suporte ( digesto@digesto.com.br ) em até 5 dias úteis após o recebimento do processo. Iremos realizar internamente novas tentativas de captura dos autos e ficará disponível, caso concluído.
Ao cadastrar uma pessoa, a busca é feita apenas pelo nome?¶
Se apenas fornecerem o nome de uma monitored_person, então só iremos considerar isto nas diversas buscas que fazemos. Recomendamos cadastrar também o CPF/CNPJ pois alguns tribunais também permitem buscas dessa forma.
Devem ser cadastradas variações fonéticas? Se sim, como?¶
Os campos “Expressão de busca” e “Expressao negativa de busca” são Expressões Regulares (regexps) então podem agrupar várias empresas numa parte monitorada única com o operador “|”. Se ao cadastrar uma nova parte monitorada vocês não especificarem essas expressões de busca, nós geramos uma padrão baseada no nome da parte fornecido. Essas expressões e novas partes podem ser modificadas por vocês a qualquer momento via API ou via Portal web Digesto Operações e passam a valer depois de dois dias.
Em geral não há necessidade para cadastrar regexps. Quando uma parte monitorada é criada, nós geramos automaticamente a expressão regular que define quais nomes vamos buscar nos tribunais, diarios etc. Esta expressão gerada e revisada pela Digesto faz o melhor esforço para capturar variações fonéticas, abreviações (COMPANHIA -> CIA) etc.
Mas se você quiser editar essa expressão que geramos, podem fazer por ai também, a API permitiria.
A expressao fica em monitored_person, campos rex e nrex.
Se voce editar uma delas (com um HTTP PATCH/POST na URL da entidade monitored_person),
então tem que setar também o campo manual_rex para true, para que a equipe Digesto não sobreescreva.
Veja um guia sobre regexps ou em português. Para mais detalhes, veja a sintaxe aceita pela API Digesto.
A OAB é utilizada na busca? Qual formato ela deve ser cadastrada?¶
Sim, nos tribunais que permitem a busca de processos por OAB do advogado.
Também são buscadas nos diários oficiais. Colocamos a descrição do campo oab em
monitored_person para esclarecer o formato.
É possível passar uma OAB + data e a API trazer todas as movimentações e publicações até a data informada?¶
Não temos na API uma operação única para, dado uma OAB, ela trazer todos os
processos atualizados. Precisaria primeiro fazer a chamada acima de “buscar
todos os processos de um advogado (/api/tribprocs/buscar)” e depois fazer uma
chamada em “obter detalhes de um processo judicial
/api/tribproc/0016377-46.2015.8.07.0003?tipo_numero=5&atualiza_tribunal=true”
para atualizarmos uma primeira vez no tribunal cada um dos processos. É
possivel cadastrar processos na API para monitoramento diário nos
tribunais/diarios oficiais (/api/proc).
Quando a distribuição for encontrada pelo CPF, vem algo dizendo isso?¶
Nesse caso não é feita distinção.
A distribuição vai informar que ela tem como fonte a pessoa monitorada onde você configurou o nome e CPF, através do campo source_url:
"source_url": ["https://op.digesto.com.br/api/monitored_person/53"],
No momento não informamos como o processo foi descoberto (se via busca de nome, cpf etc).
Ao cadastrar o regex (para variações fonéticas) devemos adicionar nele a OAB ou as buscas são feitas de forma independente?¶
São independentes.
Caso o campo is_monitored_diario da monitored_person seja true,
para todo recorte novo que chega, consideramos o que estiver nos campos rex, nrex e oab da
pessoa monitorada.
Em qual evento ou lugar podemos pesquisar para trazer as audiências, e caso necessário, atualizações dos dados das audiências?¶
Para monitorar audiências, primeiro você
define quais são os processos a serem monitorados
registrando que o processo é monitorado no
tribunal (is_monitored_tribunal = true). Então passamos a monitorar esse
processo diariamente no tribunal e quando algum detalhe de audiência
mudar, enviamos um evento de tipo 7, conforme estes detalhes.
Como monitorar palavras quaisquer em diários, mas com o resultado vindo estruturado como recorte?¶
Basta cadastrá-las como monitored_person, mas com o campo is_advogado = false,
is_monitored_diario = true e is_monitored_tribunal = false.
O que acontece caso o processo tenha sido cadastrado com número errado?¶
Se você registrar um número inválido por exemplo ou que não exista nos tribunais, ele apenas não vai gerar nenhum evento (movimentacoes, publicacoes etc), porém será contabilizado como algo monitorado. Há casos de CNJ inválidos que existem nos tribunais, e há casos de tribunais onde conseguimos monitorar o processo a partir de número não-CNJ, então não podemos descartar no momento do cadastro números inválidos.
Quando você registra um processo para monitoramento na API, ela retorna um JSON no corpo da resposta com a
URL (op.digesto.com.br/api/proc/3333) do processo recem-registrado para monitoramento. Pela API você pode então apagar este
processo para parar de monitora-lo (HTTP DELETE op.digesto.com.br/api/proc/3333) ou listar os processos monitorados
com (HTTP GET op.digesto.com.br/api/proc).
Qual a relação entre empresas, pastas e processos?¶
Deve-se cadastrar o processo dentro de uma pasta. Uma pasta pertence a uma empresa. Use diferentes empresas para representar diferentes clientes de seu software jurídico.
Os processos recem-cadastrados ficam numa pasta (proc_set) genérica. Após o cadastro do processo na API é possível move-lo para um proc_set específico.
Usuários e Empresas¶
Devemos separar nossos clientes através de Empresas na API?¶
Sim, cada cliente final seria uma user_company filha da user_company principal.
Uma empresa é composta de usuários do sistema e por processos e partes monitoradas.
Diversas outras entidades na API também estão atreladas a uma user_company.
Para criar novas empresas na API, veja mais sobre empresas-filhas.
Recomendamos por exemplo ter uma user_company para produção, outra para desenvolvimento e outra para fins de
demonstração comercial.
Devemos primeiro criar a empresa e depois o usuário? Como criar o usuário dentro da empresa?¶
Detalhamos melhor essa dinâmica em mais sobre empresas-filhas.
Toda chamada à API está associada a um user e deve ser feito com o token de acesso deste usuário.
Todos os recursos criados e listados pertencerão à user_company associada a este usuário.
A recomendação então é criar a empresa filha com o token da API da empresa-pai e na sequencia recuperar o token de API de API do usuário admin da nova empresa filha.
As chamadas da API para a nova empresa filha devem então ser feitas com esse token recuperado.
Se você não quiser/precisar organizar os processos monitorados das user_company em pastas dentro da API,
não há necessidade de ficar criando pastas. Elas vão todas por default para uma pasta “Geral” de cada user_company.
Volume de uso e Cobrança da API¶
Como é medido o volume de uso dos processos e partes monitoradas?¶
Fazemos o faturamento sempre no inicio de um mês, olhando para o consumo do mês que acabou de passar.
Em relação a processos monitorados, fazemos então uma medição logo no inicio de um mês, considerando todos os processos com monitoramento ativo naquele momento e que foram registrados para monitoramento dentro do mês anterior.
Dados da base judicial¶
Qual a diferença entre o campo vara e o vara_original¶
O vara seria usado caso no cadastro precisem do número como inteiro, ou seja, como o número cardinal da vara.
Se não precisarem de tratamento nenhum e o campo do lado do cliente for um texto por extenso com o nome da vara exatamente como informado pelo tribunal, melhor usar o vara_original.
Exemplos de como os campos se comportam:
- vara_original -> vara (quando um for assim, o outro virá assim)
- “terceira vara civel” -> “3”
- “43” -> “43”
- “34a vara cível” -> “34”
- “vara penal única” -> “vara penal única”
Repare que o vara as vezes perde informação, porém é mais estável em relação às muitas grafias usadas pelos tribunais.
Porque alguns processos aparecem com advogados sem uma parte associada?¶
Em alguns tribunais, como o TJRJ há muitos casos onde a consulta deslogada não traz a informação de qual parte o advogado pertence. Então não seria um erro, é algo esperado, e salvamos em nossa base judicial dessa forma para a informação (de que aquele advogado pertence àquele processo) dessa forma.
Quais os domínios ou IPs para URLs de download de autos usados pela Digesto?¶
Fazemos uso dos seguintes serviços para entregar os anexos: Google Cloud Storage, AWS S3, AWS Cloudfront, Cloudflare. Estes variam com moderada frequência suas faixas de endereços IP, de forma que um controle via endereços IP corre o risco de gerar bloqueios indevidos repentinamente.
Podemos construir e disponibilizar uma chamada HTTP em nossa API REST que receberia um endereço do anexo solicitado e retornaria o conteúdo do arquivo, uma espécie de proxy, porém haverá custo adicional por anexo solicitado.
Caso precise de lista fixa de IPs para download dos autos, uma alternativa que imaginamos é levantar e atualizar diariamente todas as faixas de IPs usados por esses serviços cloud e liberar/bloquear conforme forem mudando. Outra alternativa é eles fazerem o controle na camada de aplicação (endereço HTTP em um desses 3 dominios) ou algum tipo de lookup reverso que verifique se o nome DNS associado aos IPs requisitados batem com esses 3 dominios.
Quais os ranges de IPs que vocês vão utilizar para requisitar nosso serviço?¶
Usamos GCloud para nossa infraestrutura de computação, com cargas de trabalho responsáveis por fazer as chamadas de webhook a clientes externos alocadas de forma dinâmica dentro da núvem. Assim, a faixa de IPs de saída para as chamadas pela internet é bem grande.
Este arquivo traz todas as faixas de IPs usadas por nós, em notação CIDR. Para chegar na lista completa usada por nós basta considerar apenas as entradas onde o campo “scope” tem valor “us-east1”.
Cobertura¶
Processos de natureza tributária fazem parte da cobertura?¶
Se for processo judicial de natureza tributária sim.
Repare que processos administrativos tributários não fazem parte de nossa cobertura.
Nossa cobertura completa é atualizada constantemente nesta página.